
The AI Antitrust War, The Rise of Specialist Models, and a 60-Year-Old Algorithm Dethroned | Wednesday, August 27th, 2025
Welcome to The TechX Newsletter,
This week, it's all about reinvention. From a high-stakes legal battle that could reshape the AI ecosystem to the fundamental architectures and algorithms that power it, the rulebook is being thrown out. We're talking smarter, faster, and more specialised systems. Let's dive in.
The News
Musk vs Apple & OpenAI: The AI Antitrust Battle Is Here

What happens when the world’s most valuable company and the leading AI lab team up? According to Elon Musk, it’s a monopolistic conspiracy, and he’s taking them to court to prove it. The CEO of xAI has filed a major antitrust lawsuit against Apple and OpenAI, accusing them of colluding to dominate the AI landscape and crush competitors.
The core of the lawsuit is Apple's deep integration of ChatGPT into its operating system. Musk alleges this partnership isn't just a feature, it's a strategic move to create an unbeatable monopoly. By giving ChatGPT preferential treatment, he argues, Apple effectively forces its billion-plus users to favour OpenAI’s technology, making it nearly impossible for other AI models like Grok to compete on a level playing field. OpenAI has dismissed the suit as "harassment," but the legal battle raises fundamental questions about fairness and competition in the AI era.
The lawsuit is built on three central claims:
-
Antitrust Collusion: Musk alleges that Apple and OpenAI have an illegal arrangement to "lock up markets" and maintain their dominance, preventing innovators like xAI from competing.
-
Unfair Ecosystem Advantage: The suit claims that by embedding ChatGPT as a default, Apple is making it impossible for any other AI company to reach the top spot in the App Store.
-
Data Monopoly: This partnership grants ChatGPT privileged access to a massive stream of iPhone user queries, creating a powerful feedback loop that allows it to develop and improve far faster than its rivals.
This high-stakes legal showdown isn't just about corporate rivalries; it's a fight that could redefine the rules of competition for the entire AI industry.
Read more
----------------------------
A New Algorithm Dethrones a 60-Year-Old King
For six decades, Dijkstra’s algorithm has been the undisputed champion of finding the shortest path, a foundational pillar of our digital world. But what if the unbeatable was just waiting for a smarter challenger? A brilliant new paper reveals that a long-held barrier in computer science has finally been broken.
Researchers from Tsinghua University, Stanford, and the Max Planck Institute have unveiled a groundbreaking algorithm that dethrones the legendary Dijkstra's. For 60 years, all shortest-path algorithms were limited by a "sorting barrier"—the need to meticulously sort every possible next step, which consumes massive amounts of time on large networks. This new approach cleverly sidesteps that problem with a "divide and conquer" strategy, using scouts to identify crucial network "pivots" first.
-
A Smarter Approach: Instead of a slow, step-by-step exploration, the new algorithm identifies the most important intersections and explores from those key points, drastically reducing sorting time.
-
Real-World Speed: This means faster calculations for everything from your next food delivery and global internet traffic to smarter public transport and even bioinformatics research.
-
Fundamental Shift: It’s a complete rethinking of a problem computer scientists thought was solved, opening the door to new innovations.
This breakthrough is a powerful reminder that even the most established ideas are ready to be disrupted, paving the way for a faster and more efficient future.
Research paper
----------------------------
RAG is Dead, Context Engineering is King
Is Retrieval-Augmented Generation (RAG) already a thing of the past? As AI systems evolve from simple chatbots to complex agents, a new discipline is taking center stage: Context Engineering. This is the new frontier for building intelligent systems that don't break as they scale.
According to Jeff Huber from the vector database company Chroma, the old model of just retrieving documents and stuffing them into a prompt is no longer enough. As AI agents become more sophisticated and context windows grow, the real challenge is figuring out precisely what information should be in the context window at every single step. This requires a more nuanced approach, one that actively manages and optimizes the data fed to the language model to ensure it's always relevant and high-quality.
-
A Shift in Focus: The industry is moving beyond basic retrieval to the art and science of "context engineering"—intelligently curating the information an LLM uses to reason.
-
Inner and Outer Loops: This involves two key processes: an "inner loop" for setting up the context for an immediate task, and an "outer loop" for continuously improving how the system selects relevant information over time.
-
Preventing System Rot: As your knowledge base grows, context engineering is crucial for preventing your AI systems from degrading in performance and delivering irrelevant results.
This isn't just a technical shift, it's a fundamental change in how we build and maintain AI systems, ensuring they remain impactful and intelligent as they tackle increasingly complex tasks.
Read more
The Topic
How AI Learned to Delegate: An Intro to Mixture of Experts (MoE)
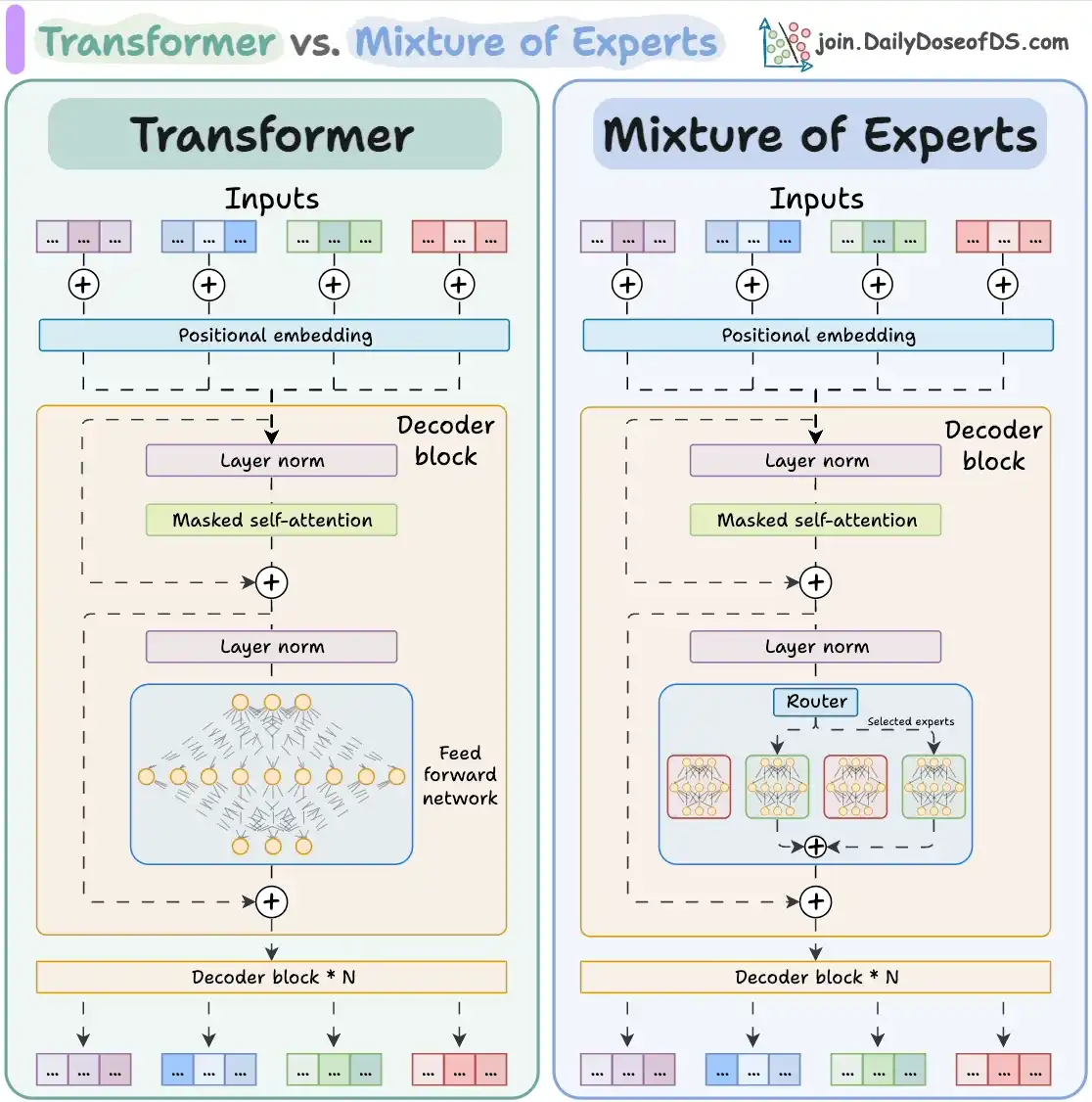
Imagine you need to solve a complex legal problem, a medical diagnosis, and a software bug all at once. The old way of building AI was like having a single, genius-level generalist try to tackle all three. They're smart, but they have to mentally load the entirety of their knowledge on law, then medicine, then code for each task. It's incredibly inefficient and they're an expert in none of them.
Now, imagine a different approach. You have a highly-competent team manager. You hand them the three problems. The manager instantly assesses them and says: "The legal issue goes to our top lawyer, the medical query goes to our chief physician, and the bug goes to our senior developer." Each problem is delegated to a world-class specialist who can solve it faster and more accurately. The manager's only job is to be an expert at routing.
This is the brilliant, brutally efficient architecture behind today's top AI models: Mixture of Experts (MoE). It’s the transition from a single, overworked brain to a coordinated team of specialists.
The Story: The "Dense" vs. "Sparse" Revolution
The Old Way (Dense Models): For years, the race in AI was to build bigger "dense" models. Think of a model like GPT-3. In a dense model, every single part of its massive neural network has to "wake up" and process every piece of information you give it. If you ask it to write a poem, the parts of its brain that know about quantum physics and C++ programming are forced to activate and participate. This is computationally insane. It's like forcing an entire hospital—from the brain surgeons to the administrative staff—to be present for every single patient consultation. The result is powerful, but incredibly slow and expensive to run.
The New Way (Sparse MoE Models): Mixture of Experts introduces a "sparse" approach. The model can be gigantic in its total number of parameters (experts), but only a tiny fraction of them—the most relevant specialists—are activated for any given task. This is called sparse activation. When you ask an MoE model like Mixtral to write a poem, the "router" instantly identifies the "poetry expert" and the "grammar expert." The "coding expert" and "physics expert" remain dormant, saving massive amounts of computational power. This allows for models with a huge total parameter count (giving them vast knowledge) to operate at the speed and cost of a much smaller model. It’s the secret to achieving massive scale with startling efficiency.
The Architecture of Delegation: A Technical Look
An MoE model isn't a single network but a system of components working in perfect harmony, typically within each block of a transformer.
The Experts: These are smaller, independent neural networks (usually feed-forward layers). During training, each expert naturally begins to specialize in different types of data or tasks. One might become a master of Python code, another at parsing legal documents, and a third at creative writing.
The Gating Network (or "Router"): This is the team manager. The router is a small but critical neural network that examines the input token (a word or part of a word). Its sole job is to decide which of the available experts are best suited to handle this specific piece of information. It then generates a signal that "activates" only those selected experts.
The Aggregator: Once the selected experts have processed the information in parallel, their outputs are combined. The router's decision is used to create a weighted average of the expert outputs, giving more influence to the expert it deemed most relevant. This combined result becomes the final output for that step.
What You Need to Build an MoE System
A Set of Expert Sub-Networks: Instead of one large feed-forward network in your transformer block, you define multiple smaller ones. You can have 8, 16, or even 64+ experts.
A Gating Network: A separate, small, trainable network that takes sequence tokens as input and outputs a probability distribution over the experts.
An Orchestration Logic: Code that uses the output of the gating network to selectively route the input to the top-k experts (usually k=2).
A Combination Mechanism: A method to intelligently merge the outputs from the activated experts, typically a weighted sum based on the router's probabilities.
The Toolkit
This open-source, AI-powered platform uses a suite of specialized agents to automate software development. DeepCode can process inputs like research papers or plain language specs and transform them directly into production-grade, full-stack applications, complete with frontend, backend, and automated tests.
Get it on GitHub
Tana: The AI-Powered Knowledge OS:
A powerful new tool that merges your notes, tasks, and knowledge into a single, interconnected system. Tana allows you to capture everything in a daily log and then structure your thoughts on the fly using a flexible, AI-powered knowledge graph. It’s designed to be your "everything OS," adapting to your unique workflow rather than forcing you into a rigid structure.
Try it out!
The Bytes
- Anthropic Boosts AI in Higher Education with New Advisory Board and Courses: Anthropic is launching two major initiatives to guide the responsible integration of AI in universities, including a Higher Education Advisory Board of academic leaders and three open-access AI Fluency courses designed for both educators and students to build practical, ethical AI skills.
- Apple’s Reverse Charging Tested for iPhone 17 Pro: Apple is reportedly testing a reverse wireless charging feature for the upcoming iPhone 17 Pro models, enabling users to power other devices from their phone, alongside new battery and camera upgrades.
- OpenAI Launches India-Focused Education Initiative: OpenAI introduced its first major education program in India aimed at empowering teachers and students with AI tools and training, supporting classroom transformation with intelligent solutions.
The Resources
-
[Design Pattern] Why Enterprises Are Moving to Multi-Agent AI Systems:
This Microsoft Dev Blog post explains the enterprise shift from single, monolithic AI agents to sophisticated multi-agent systems. While single agents are great for narrow tasks, they collapse under real-world business complexity. The new approach uses collections of specialized agents that collaborate to solve problems, mirroring how human teams work and unlocking powerful emergent intelligence. Read on Microsoft Dev Blogs -
[Study Guide] Master System Design with This Open-Source Primer:
This popular GitHub repository is an organized collection of resources to help you learn how to design large-scale, scalable systems. It’s an essential guide for engineers looking to level up and a critical prep tool for technical interviews, featuring common questions and detailed sample solutions. Explore on GitHub - [Research] Intern-S1, a Specialized AI Generalist for Scientific Discovery:
This new paper introduces Intern-S1, a 241-billion parameter multimodal Mixture-of-Experts (MoE) model designed to bridge the performance gap between open-source and closed-source AI in challenging scientific fields. It excels at analyzing complex science data, outperforming existing models in specialized tasks like molecular synthesis planning and reaction condition prediction. Read the paper on Hugging Face
And that's a wrap. The big theme this week is the clear pivot from brute force to intelligent design at every level of the stack. As our tools become hyper-specialized, the big question is how our own roles will evolve alongside them. Stay curious!
![]()
![]()
